Building an MLOps Pipeline with Apache Airflow (Part 1)
Let's first understand what's MLOps.
What is MLOps?
MLOps (Machine Learning Operations) is a set of practices and tools used to manage the entire lifecycle of machine learning models. MLOps includes everything from data preparation and model training to deployment, monitoring, and ongoing maintenance.
The primary goal of MLOps is to create a streamlined and automated process for deploying and managing machine learning models at scale. This requires collaboration between data scientists, software engineers, operations teams, and advanced tools and technologies.
Some of the key components of MLOps include:
Version control: Tracking changes to the code and models over time, enabling reproducibility and collaboration between team members.
Continuous integration and delivery (CI/CD): Automating the process of testing, building, and deploying models to production environments, reducing the risk of errors and downtime.
Infrastructure as code (IaC): Treating infrastructure as software, enabling the automated and reproducible deployment of models and related infrastructure.
Monitoring and alerting: Tracking model performance and detecting issues in real-time, enabling proactive maintenance and optimization.
Governance and compliance: Ensuring that models comply with relevant regulations and ethical standards while enabling easy auditing and traceability.
Different Components of Machine Learning Workflow
To automate and manage the entire lifecycle of ML models, we need to understand what's the workflow of an ML product.
Largely, we can divide the entire process in three parts:
- Experiment and develop
- Operationalize
- Orchestrate
Experiment and Develop
In the experiment and develop phase, we explore the data, perform feature engineering, select models, train and evaluate models, and tune hyperparameters to get the best model performance. We must keep track of all the trials and their outcomes because this phase involves a lot of experimentation.
- Data featurization: The first step is to gather and transform data into a format the ML algorithm can understand. This technique is called data featurization. We must perform feature engineering to select relevant features, convert the data into numerical values, and handle missing data.
- Modeling: The next step is to select the appropriate ML model for the given problem. We can choose from several models, such as linear regression, logistic regression, decision trees, random forests, support vector machines, and neural networks. We need to select the best model based on the problem statement, the data, and the evaluation metrics.
- Training and evaluation: After selecting the model, we need to train it on the data and evaluate its performance. We can split the data into training, validation, and testing sets to evaluate the model's performance. We need to keep track of the training and evaluation metrics for each experiment.
Operationalize
In the operationalize phase, we need to design the ML architecture, scale it to handle large volumes of data, and ensure that it is reliable and secure.
- Architecture: We need to design the ML architecture that meets the business requirements and integrates with other systems in the organization. We can choose from various architectures such as batch processing, real-time processing, microservices, and serverless.
- Scaling: We need to scale the ML architecture to handle large volumes of data and handle multiple requests in parallel. We can use horizontal scaling by adding more servers or vertical scaling by adding more resources to the existing server.
- Reliability: We need to ensure that the ML architecture is reliable and can handle failures gracefully. We need to design the architecture to be fault-tolerant and use monitoring and alerting to detect and resolve issues.
Orchestrate
In the orchestrate phase, we need to automate the entire ML workflow from model training to deployment and monitor the deployed models' performance.
- Scheduling: We need to schedule the ML workflows to run at regular intervals, such as daily, weekly, or monthly. We can use workflow orchestration tools such as Apache Airflow to schedule and manage the workflows.
- Versioning and serving: We need to version the ML models to keep track of changes and deploy the latest version of the model. We can use containerization tools such as Docker to package the ML models and deploy them to production.
- Monitoring and Governance: We need to monitor the performance of the deployed models and ensure that they meet the business requirements. We can use monitoring and governance tools to detect and resolve issues, ensure compliance with regulations, and maintain the model's fairness and accuracy.
Steps to Develop an End-to-End Machine Learning Project
Developing an AI/ML application involves several steps:
- Clarify the business requirements
- Assess available data
- Develop data science pipeline
- Deploy model
- Maintain the model operations
So, if we think of this as an ML application lifecycle, how do we actually achieve it?
There are numerous ways in which it's currently being achieved by various teams at various institutions. There is no standard or hard core rule to achieve this lifecycle. It depends on your needs. Few of the tools that people use heavily to achieve this lifecycle are listed below:
| Productionized Notebooks | MLOps Platforms | Custom Pipelines |
|---|---|---|
| AWS SageMaker | Kubeflow | Python/R |
| GCP Vertex AI Notebooks | AWS SageMaker | SQL |
| Databricks | Azure ML | Apache Airflow |
| Papermil | Vertex AI | Metaflow |
| Kedro | Git | |
| H2O | Circle CI |
Typical End-to-End ML Pipeline
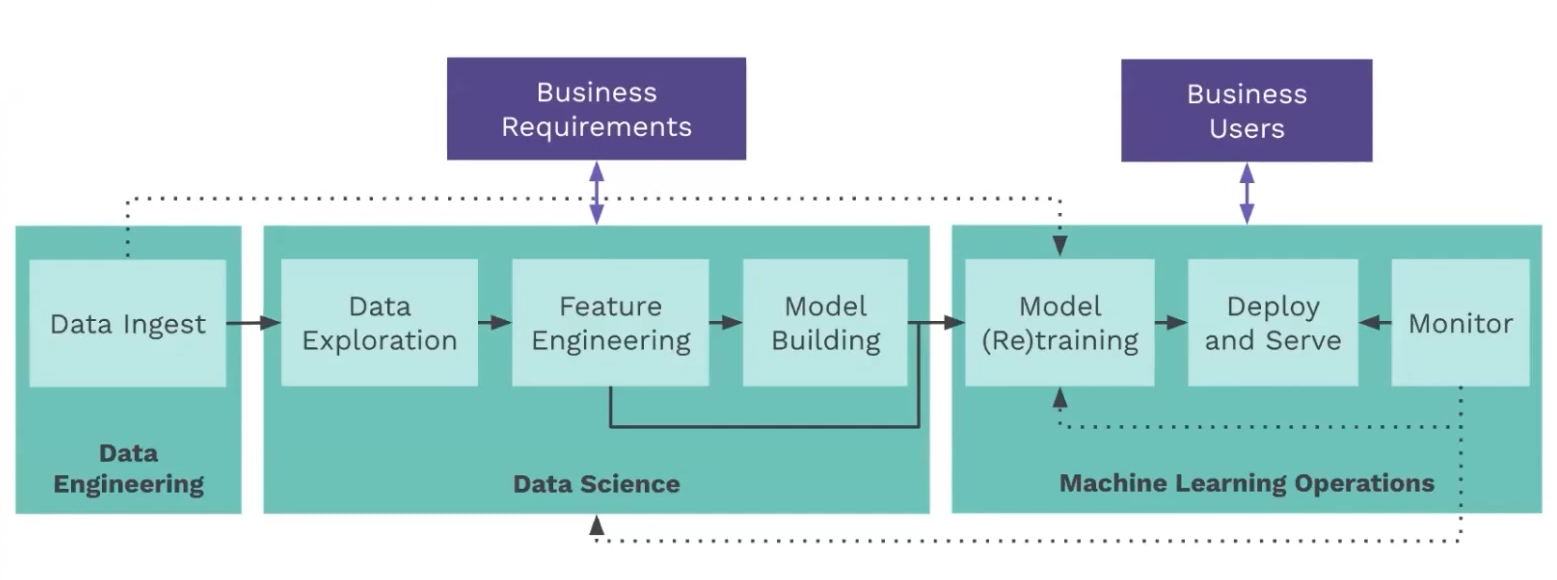
This is again going into the different steps of end-to-end ML pipelines. We start with Data Ingestion which falls on Data Engineering. Then we have Data Exploration, Feature Engineering, and Model Building, a more experimental phase that falls under Data Science. Once the model is trained, we move to the MLOps aspect, where we define how the model will be retrained, how often the model is going to be retrained, how to deploy/serve the model at scale, and monitoring the model performance in production.
At each of these stages, we are going to work with our business counterparts to define the requirements and make sure that our product is adding value to the users.
Now, which of the above steps are automatable?
Exploration and Experimentation in Data Science part is not usually automatable because we need continuous research to improve these steps. However, rest of the part is automatable.
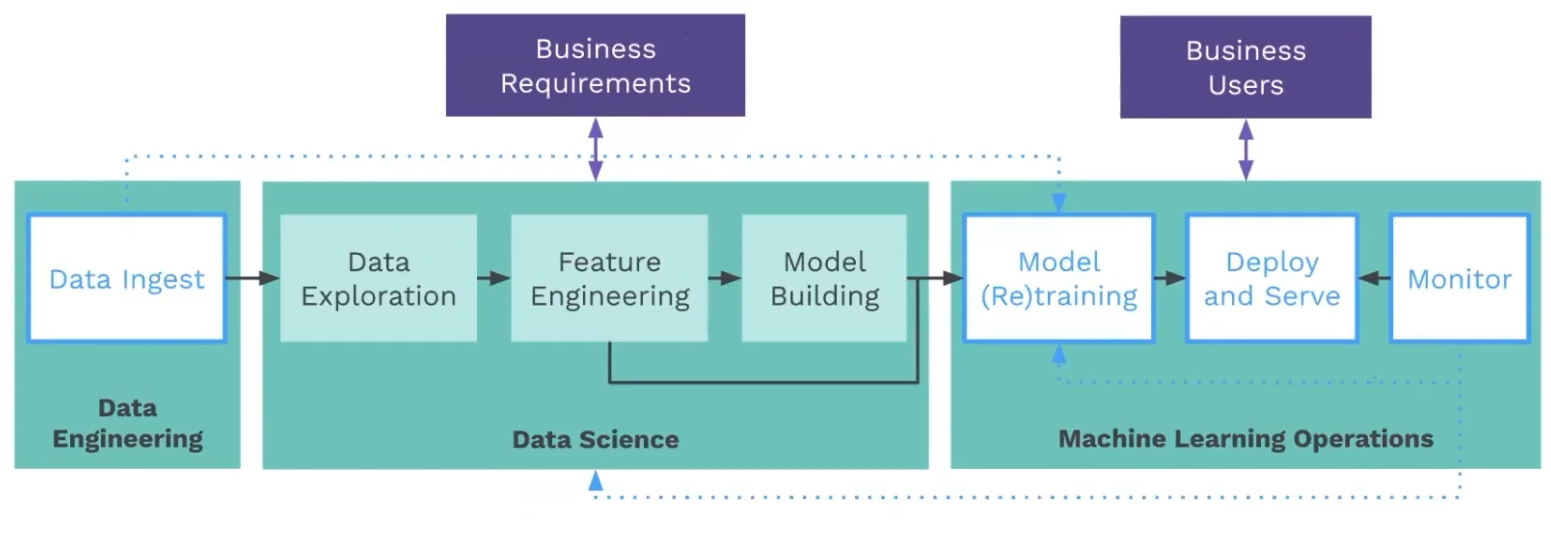
In fact, we can use the the Monitoring to trigger the pipeline to circle back to the Data Science phase of feature engineering and model optimization, when a model is not performing well. So, the automated production pipeline includes ingestion, featurization, model training, deployment, and monitoring, all of which can be accomplished using the Python-native tool Airflow.
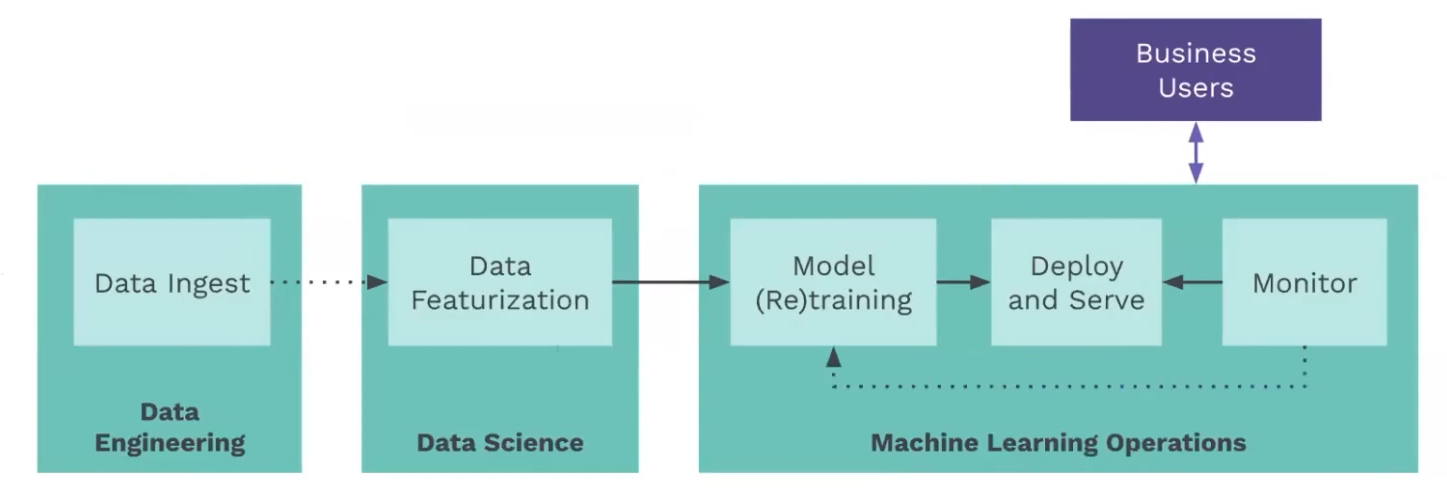
Automating with Airflow
So, why should we use Airflow?
Airflow is a Python-native tool that data scientists and ML engineers commonly use due to its integration with many other tools such as TensorFlow, SageMaker, MLflow, and Spark. Airflow has great features for logging, monitoring, and alerting and is extensible, allowing the writing of custom operators. It is also pluggable for compute, elastic, data-aware, and cloud-neutral. The automated parts of the pipeline can be scheduled, and dependencies can be set using sensors or by directly triggering one part from another. The text notes that one can write separate dags for each pipeline stage, such as training, validation, deployment, and prediction. The metadata and data can be passed between tasks to enable communication and agreement on inputs and outputs.
DAG - Data Structure of Airflow
DAG stands for Directed Acyclic Graph in Airflow. In Airflow, A DAG in Airflow is a group of tasks with dependencies on one another that are shown as nodes in a graph. Tasks are represented as nodes in the graph, and their dependencies are shown as edges. The graph is directed, meaning that the edges point from upstream tasks to downstream tasks, indicating that the downstream tasks depend on the upstream tasks to be completed first.
The graph is also acyclic, meaning there are no circular dependencies, i.e., no tasks depend on themselves or each other in a circular manner. This ensures that the tasks can be executed in a logical order without any infinite loops. Airflow uses the DAG concept to schedule and execute workflows consisting of multiple tasks. The user defines a DAG in Python code, including the tasks and their dependencies. Airflow manages the scheduling and execution of the tasks according to the dependencies defined in the DAG.
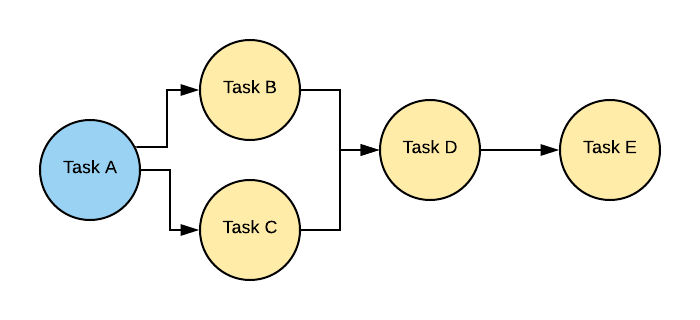
If you notice the above graph, Task B dependent on Task A, Task D dependent on Task B and Task C, and so on. It's an acyclic graph, which means there is no cycle. These types of graphs can be executed through Airflow. If there were circular dependencies, then Airflow couldn't execute those tasks.
This is the first part of this tutorial. Here, we explained the theoretical aspects of designing MLOps pipelines and why we can consider Apache Airflow for orchestrating our pipeline. In the second part of this tutorial, I will demonstrate how to develop an MLOps pipeline using Airflow code samples.
Author: Sadman Kabir Soumik
References:
[1] https://airflow.apache.org/docs/apache-airflow/stable/