How Generative AI Works - ChatGPT, Midjourney, and Dall-E Demystified
Generative AI is a subset of artificial intelligence that creates completely new content, like images, videos, music, and text. It uses machine learning to find patterns in existing data and make new content based on these patterns. Generative AI is growing fast and could change many industries, like entertainment and healthcare. There are many great generative AI tools today, like DeepMind's Alpha Code, ChatGPT, DALL-E, MidJourney, Jasper, and GitHub Copilot.
How does Generative AI work?
Generative AI is a technology that uses deep learning algorithms to make new data. These programs learn from big collections of existing data, like pictures or writing, and then use that to create new content. There are many kinds of generative models, such as:
- Generative Adversarial Networks (GAN)
- Variational Auto-encoders (VAE)
- Diffusion Models
- Deep Auto-Regressive Models
Generative Adversarial Networks (GANs)
GANs consist of two neural networks that work together: a generator and a discriminator. The generator creates new data that is similar to the training data, and the discriminator evaluates whether the generated data is real or fake. The two networks are trained together, with the generator trying to create data that the discriminator cannot distinguish from real data.
When training begins, the generator produces obviously fake data, and the discriminator quickly learns to tell that it's fake:

As training progresses, the generator gets closer to producing output that can fool the discriminator:

Finally, if generator training goes well, the discriminator gets worse at telling the difference between real and fake. It starts to classify fake data as real, and its accuracy decreases.

Here's a picture of the whole system:

Both the generator and the discriminator are neural networks. The generator output is connected directly to the discriminator input. Through backpropagation, the discriminator's classification provides a signal that the generator uses to update its weights. Read more here.
Variational Auto Encoders (VAE)
An autoencoder and a variational autoencoder (VAE) are types of neural networks used for unsupervised learning tasks. They both consist of an encoder network and a decoder network. The encoder network maps the input data to a lower-dimensional latent space, while the decoder network maps the latent space back to the original data space.
However, the main difference between them is how they generate the latent space. Autoencoders generate a fixed latent space, while VAEs generate a probabilistic latent space, which allows them to sample from the latent space during the decoding process, resulting in more diverse outputs than autoencoders.
Additionally, VAEs can learn the underlying distribution of the input data and generate new samples by sampling from the learned distribution in the latent space, making them especially useful for generating new, realistic data samples in applications such as image or music generation. On the other hand, autoencoders are better suited for tasks such as feature extraction and data compression.
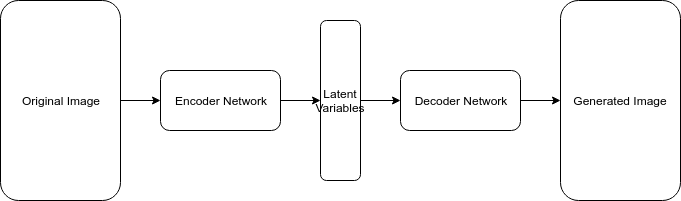
Diffusion Models
You probably heard of tools like DALL-E, which was released by OpenAI. DALL-E 2 uses a type of diffusion model.
GAN models are often characterized by unstable training and limited diversity in generation because of their adversarial training approach. VAE relies on a surrogate loss, while flow models require specialized architectures to construct reversible transforms.
Diffusion models are a type of machine learning model that use non-equilibrium thermodynamics as inspiration. They create a step-by-step process to add random noise to data, and then learn how to reverse that process in order to generate samples that match the original data. Unlike other models, such as VAE or flow models, diffusion models use a fixed learning procedure and the latent variable has high dimensionality, meaning it has the same number of dimensions as the original data. Read more from here.
Diffusion models are machine learning systems that are trained to denoise random gaussian noise step by step, to get to a sample of interest, such as an image. The underlying model, often a neural network, is trained to predict a way to slightly denoise the image in each step. After certain number of steps, a sample is obtained.
The process is illustrated by the following design:

The architecture of the neural network, referred to as model, commonly follows the UNet architecture as proposed in this paper and improved upon in the Pixel++ paper.
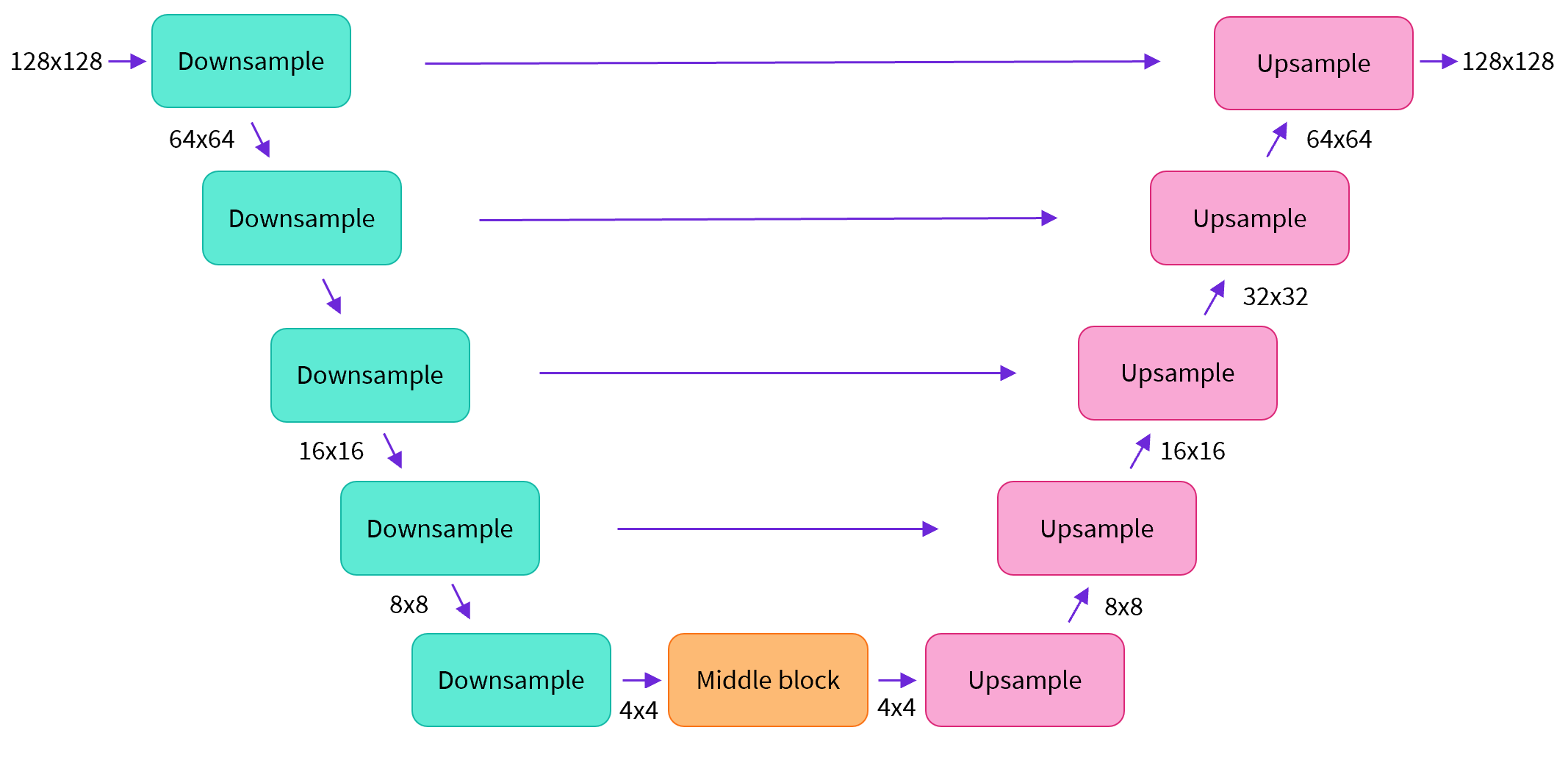
Some of the highlights of the architecture are:
- The model outputs images of the same size as the input.
- The input image is processed through several blocks of ResNet layers, which reduces its size by half.
- The image is then processed through the same number of blocks that upsample it again.
- The architecture has skip connections which link features on the downsample path to corresponding layers in the upsample path, improving the quality of the output.
Some examples of Diffusion models are:
- DALL-E 2
- Midjourney
- Stable Diffusion
- Imagen
Deep Auto-regressive Models
"Auto-regressive" models are a type of statistical model that uses past values of a time series to predict future values. The basic idea behind auto-regressive models is that the value of a time series at any given time point is a function of its previous values. In other words, the value at time t depends on the values at times t-1, t-2, t-3, and so on.
Auto-regressive models are commonly used in time series forecasting applications, such as predicting stock prices, weather patterns, or traffic volumes. One example of an auto-regressive model is the Auto-Regressive Integrated Moving Average (ARIMA) model.
On the other hand, deep autoregressive models, which are a type of neural network that can generate sequential data such as text, speech or images. Deep autoregressive models are different from recurrent neural networks (RNNs) type of sequential models because they do not have feedback loops or hidden states. Instead, they use feed-forward layers and conditional probabilities to model the dependencies between inputs and outputs. Deep autoregressive models are also different from generative adversarial networks (GANs) or variational autoencoders (VAEs) because they do not rely on latent variables or adversarial training. Instead, they use maximum likelihood estimation and teacher forcing to learn from supervised data.
Transformers based architecture is an great example of deep autoregressive models. The Illustrated Transformer is an excellent blog on how Transformer works.
Some examples of deep autoregressive models are:
- Transformers (GPT3/3.5 is based on Transformer architecture. )
- PixelRNN
- WaveNet
Author: Sadman Kabir Soumik
References:
[1] https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
[2] https://developers.google.com/machine-learning/gan
[3] https://github.com/huggingface/diffusers
[4] https://data-science-blog.com/blog/2022/03/15/deep-autoregressive-models/