Ace Your Data Science Interview - Top Questions With Answers
What are some common challenges faced in a data science project?
- Finding and acquiring relevant and high-quality data: This can be a challenge because data is often scattered across multiple sources and may be in different formats. Data scientists must be able to find and access the data they need, and then clean and preprocess it to make it ready for analysis.
- Cleaning and preprocessing the data: Before the data can be analyzed, it must be cleaned and preprocessed to remove errors, inconsistencies, and missing values. This can be a time-consuming and labor-intensive process, but it is critical for ensuring that the results of the analysis are accurate and reliable.
- Handling large and complex data sets: Many data science projects involve working with large and complex data sets, which can be difficult to manage and analyze using traditional methods. Data scientists must be able to use advanced techniques and tools to efficiently and effectively handle these data sets.
- Choosing the appropriate algorithms and techniques: There are many different algorithms and techniques that can be used for data analysis, and choosing the right ones is essential for ensuring that the results of the analysis are accurate and meaningful. Data scientists must be familiar with a wide range of algorithms and techniques and be able to select the ones that are best suited for the data and the problem at hand.
- Validation and evaluation of results: After the analysis is complete, the results must be validated and evaluated to ensure that they are accurate and reliable. This can involve testing the results using different methods and techniques, comparing the results to known benchmarks, and getting feedback from stakeholders.
- Communicating the results: Finally, data scientists must be able to effectively communicate the results of their analysis to stakeholders. This may involve creating visualizations and reports, presenting the results to different audiences, and explaining the findings in a clear and concise manner.
- Model explainability is an important aspect of many data science projects, especially when the results of the analysis are used to make decisions that impact people's lives. Explainability refers to the ability to understand and interpret the results of a machine learning model, and it is important because it can help to ensure that the model is fair, transparent, and accountable.
Can you discuss the differences between unsupervised, semi-supervised, and supervised learning?
In machine learning, there are mainly three types of learning algorithms: unsupervised, semi-supervised, and supervised.
- Unsupervised learning involves training a model on a dataset with no labels or outputs. The model must independently discover the underlying patterns and structures in the data. Examples of unsupervised learning include clustering, dimensionality reduction, and anomaly detection.
- Semi-supervised learning involves training a model on a dataset that has some, but not all, labels or outputs. The model can use the labeled data to learn the relationships between the inputs and the outputs and can then use this knowledge to make predictions on the unlabeled data. This can be useful when there needs to be more labeled data to train a supervised model, but there is enough unlabeled data to help the model learn.
- Supervised learning involves training a model on a dataset with inputs and corresponding labeled outputs. The model learns to map the inputs to the outputs and can then be used to make predictions on new, unseen data. Examples of supervised learning include regression, classification, and structured prediction.
Explain model overfitting and underfitting
In machine learning, overfitting and underfitting refer to a model performing well on the training data but poorly on new, unseen data. Overfitting occurs when a model is too complex and sensitive to the specific details of the training data. As a result, the model may perform well on the training data but poorly on new data because it has learned patterns that are specific to the training data and do not generalize to other data.
On the other hand, underfitting occurs when a model is too simple and cannot capture the underlying patterns in the data. As a result, the model may need to perform better on training or new data.
Both overfitting and underfitting can be problematic because they can lead to poor performance on the task that the model was trained for. To avoid overfitting and underfitting, data scientists must find a balance between model complexity and the amount of training data available. This often involves using techniques such as regularization to control the model's complexity and cross-validation to evaluate the model's performance on new data.
Can you explain the bias-variance trade-off and how it relates to model performance?
The bias-variance trade-off is a fundamental concept in machine learning and statistics that refers to the trade-off between the bias and the variance of a model. Bias and variance are two sources of error that can impact the performance of a machine learning model. Bias is the error that arises when a model makes assumptions about the data that are too simple or not complex enough. This can lead to underfitting, where the model is not able to capture the underlying patterns in the data. On the other hand, variance is the error that arises when a model is too complex and sensitive to small fluctuations in the data. This can lead to overfitting, where the model performs well on the training data but poorly on new, unseen data. The bias-variance trade-off refers to the fact that as the bias of a model decreases, its variance tends to increase, and vice versa. As a result, data scientists must find a balance between bias and variance to achieve good performance on the task at hand. This often involves using techniques such as regularization to control the complexity of the model and prevent overfitting.
Can you explain the concept of overfitting and how to avoid it?
Overfitting occurs when a machine learning model performs well on the training data, but poorly on new or unseen data. This happens when the model has learned the noise or random fluctuations in the training data, rather than the underlying patterns and trends. As a result, the model is not able to generalize well to new data and makes inaccurate predictions.
To avoid overfitting, there are several approaches that can be used, including:
- Using a larger training dataset: By increasing the number of training examples, the model can learn more robust and generalizable patterns from the data.
- Using regularization: This involves adding a penalty term to the cost function, which encourages the model to use simpler, more generalizable models.
- Using cross-validation: This involves dividing the training dataset into multiple sets, training the model on one set and evaluating it on the other sets. This can help identify overfitting and allow for more accurate model evaluation.
- Using early stopping: This involves monitoring the performance of the model on a validation set during training and stopping the training process when the performance on the validation set begins to decrease. This can help prevent the model from learning the noise in the training data.
- Using ensembling: This involves training multiple models on the same data and combining their predictions. This can help reduce overfitting by averaging out the noise in the individual models.
What is Transfer Learning?
Transfer learning is a machine learning technique where a model trained on one task is used as the starting point for a model on a second, related task. This can help to improve the performance of the second model by leveraging the knowledge learned from the first task.
For example, if a model is trained to recognize objects in photographs, it will learn to recognize features such as edges, textures, and shapes that are commonly found in images. This knowledge can be useful for other tasks that involve image recognition, such as classifying medical images or detecting objects in videos. By using the model trained on the first task as a starting point, the second model can learn more quickly and achieve better performance.
Transfer learning is often used in deep learning, where it can help to overcome the challenges of training large and complex models on small datasets. It is also a useful technique for adapting a model to a new domain or to improve its performance on a specific task.
Difference between parameter and hyper-parameter in Machine Learning
In machine learning, a parameter is a value that is learned by a model during training. For example, in a linear regression model, the parameters are the coefficients that are used to make predictions. These parameters are learned by the model based on the training data, and they are used to make predictions on new, unseen data.
On the other hand, a hyperparameter is a value that is set by the data scientist before training. Hyperparameters are not learned by the model during training, but they can impact the performance and behavior of the model. Examples of hyperparameters include the learning rate used by a neural network, the regularization parameter in a regularized regression model, or the number of trees in a random forest.
In general, parameters are learned by the model, while hyperparameters are set by the data scientist. Tuning the hyperparameters of a model can often improve its performance, but this requires a good understanding of the model and the data it is being applied to.
What will you do if your training data classification accuracy is 80% and test data accuracy is 60%?
If the training data classification accuracy is 80% and the test data accuracy is 60%, it is likely that the model is overfitting to the training data. This means that the model has learned patterns that are specific to the training data, but that do not generalize well to new, unseen data.
To improve the performance of the model on the test data, there are several steps that you can take:
- Use more and/or different training data: This can help the model to learn more generalizable patterns, and may improve its performance on the test data.
- Simplify the model: By reducing the complexity of the model, you can reduce the risk of overfitting and improve its performance on the test data. This can be done by using regularization or by reducing the number of parameters in the model.
- Use techniques to prevent overfitting: There are many techniques that can be used to prevent overfitting, such as early stopping, dropout, or data augmentation. These techniques can help the model to generalize better to new data.
Overall, the goal is to find a balance between model complexity and the amount of training data available, in order to achieve good performance on the test data. This often involves experimentation and trial and error to find the best combination of techniques and hyperparameters.
Test accuracy is higher than the train accuracy. What does it indicate?
If the test accuracy is higher than the training accuracy, it may indicate that the model is underfitting the training data. This means that the model is not able to capture the underlying patterns in the training data, and as a result, it does not perform well on the training data.
However, it is also possible that the test accuracy is higher than the training accuracy due to random fluctuations in the data, or because the test data is easier to classify than the training data. In this case, the model may still be overfitting to the training data, and its performance on new, unseen data may be poor.
In general, it is important to evaluate the performance of a model on both the training data and the test data, and to compare the two in order to assess the model's ability to generalize to new data. If the test accuracy is significantly higher than the training accuracy, it may be necessary to adjust the model or to use different training data in order to improve its performance.
Explain data leakage
Data leakage occurs in machine learning when information from outside the training data is used to create the model, resulting in a model that is overly optimistic and not representative of the true relationship between the features and the target variable. This can happen in a number of ways, such as using information from the test set to inform model training, or using data that is not actually available at the time the model will be used in practice. Data leakage can significantly bias model performance, leading to overly optimistic results on the training data and poor performance on new, unseen data. To prevent data leakage, it is important to carefully split the data into training and test sets, and to use only the training data to train the model.
How to improve the performance of a machine learning model?
One of the first steps in improving the performance of a machine learning model is to identify the specific problem or issue with the model's performance. This might involve analyzing the model's performance on different subsets of the data, or comparing its performance to other models. Once you have identified the problem, you can take steps to address it.
For example, if the model is overfitting to the training data, you can try using regularization techniques to constrain the model and prevent overfitting. Regularization involves adding additional constraints to the model, such as limiting the number of features or the complexity of the model, to prevent the model from fitting too closely to the training data. This can help the model learn more generalizable patterns in the data, and improve its performance on new, unseen data.
If the model is underfitting, on the other hand, you can try increasing the complexity of the model by adding more features or using a more complex model architecture. By adding more features, the model can learn more intricate patterns in the data, which can improve its performance. Similarly, using a more complex model architecture, such as a deep neural network, can allow the model to capture more complex patterns in the data and improve its performance.
Another important step in improving the performance of a machine learning model is to carefully tune the model's hyperparameters. Hyperparameters are the parameters of the model that are not learned during training, such as the learning rate or regularization strength. By carefully tuning these hyperparameters, you can help the model learn more effectively and improve its performance. This can involve using techniques such as grid search or random search to explore different combinations of hyperparameters and identify the ones that yield the best performance.
In addition to these steps, it is also important to use different evaluation metrics to assess the model's performance. Instead of using accuracy alone, you can consider using other metrics such as precision, recall, or F1 score to get a more complete picture of the model's performance. These metrics can provide a more nuanced view of the model's performance, and can help you identify areas where the model is performing well or poorly.
Finally, it is often helpful to try different approaches and techniques to improve the performance of a machine learning model. For example, you can try using ensemble methods, where multiple models are combined to make predictions, or transfer learning, where a pre-trained model is fine-tuned for a specific task. These approaches can help improve the model's performance by leveraging the strengths of multiple models or pre-existing knowledge.
Overall, improving the performance of a machine learning model involves a combination of identifying and addressing specific problems with the model, tuning the model's hyperparameters, using different evaluation metrics, and experimenting with different approaches and techniques. By following these steps, you can help your model learn more effectively and make more accurate predictions on new, unseen data.
What are the different types of regression models?
Linear Regression
Linear regression is a statistical model that is used to predict a continuous outcome variable based on one or more predictor variables. In linear regression, the relationship between the dependent and independent variables is assumed to be linear, meaning that the change in the dependent variable is proportional to the change in the independent variables.
While linear regression is a powerful and widely-used tool, it has some limitations that can cause it to perform poorly in certain cases. Some of the most common scenarios where linear regression may perform poorly include the following:
- When the relationship between the dependent and independent variables is nonlinear. Linear regression assumes that the relationship between the dependent and independent variables is linear, so it may perform poorly when the relationship is nonlinear.
- When the data is noisy or contains outliers. Linear regression can be sensitive to noise and outliers in the data, which can cause the model to fit poorly and make inaccurate predictions.
- When there are interactions or nonlinearities in the data. Linear regression is not able to model interactions or nonlinearities in the data, so it may perform poorly in these cases.
- When the data is highly correlated. Linear regression assumes that the predictor variables are independent, so it may perform poorly when the variables are highly correlated.
Polynomial Regression
Polynomial regression is a type of regression in which the relationship between the dependent and independent variables is modeled as a polynomial function. This allows the model to capture more complex, nonlinear relationships in the data, as opposed to linear regression, which assumes a linear relationship between the dependent and independent variables.
Polynomial regression is useful in situations where the relationship between the dependent and independent variables is nonlinear. For example, if you are trying to predict the price of a stock based on its performance over time, the relationship between the price and time may not be linear. In this case, using a polynomial regression model can capture the nonlinear relationship and improve the model's performance.
On the other hand, polynomial regression may not be the best choice in situations where the relationship between the dependent and independent variables is actually linear. In these cases, a linear regression model may be more appropriate, as it will be simpler and more interpretable than a polynomial regression model. Additionally, polynomial regression can be computationally expensive, so it may not be practical for very large datasets.
Lasso Regression
Lasso regression, also known as L1 regularization, is a type of regression that uses a regularization term in the cost function to penalize the complexity of the model. This regularization term, known as the L1 norm, adds a penalty based on the absolute value of the coefficients of the model, with the goal of reducing the magnitude of the coefficients and limiting the model's complexity.
Lasso regression is useful in situations where the number of predictor variables is very large, and some of the predictor variables are not actually relevant for predicting the outcome variable. By using the L1 regularization term, Lasso regression can automatically select the most important predictor variables and ignore the others, reducing the model's complexity and improving its performance.
On the other hand, Lasso regression may not be the best choice in situations where the number of predictor variables is small, or where all of the predictor variables are equally important. In these cases, Lasso regression may select only a few predictor variables and ignore the rest, potentially leading to poorer performance. Additionally, Lasso regression may perform poorly when the predictor variables are highly correlated, as it can only select one of the correlated variables.
Ridge Regression
Ridge regression, also known as L2 regularization, is a type of regression that uses a regularization term in the cost function to penalize the complexity of the model. This regularization term, known as the L2 norm, adds a penalty based on the squared value of the coefficients of the model, with the goal of reducing the magnitude of the coefficients and limiting the model's complexity.
Ridge regression is useful in situations where the number of predictor variables is very large, and some of the predictor variables are not actually relevant for predicting the outcome variable. By using the L2 regularization term, Ridge regression can automatically reduce the magnitude of the coefficients of the less important predictor variables, reducing the model's complexity and improving its performance.
On the other hand, Ridge regression may not be the best choice in situations where the number of predictor variables is small, or where all of the predictor variables are equally important. In these cases, Ridge regression may still reduce the magnitude of the coefficients of the less important predictor variables, potentially leading to poorer performance. Additionally, Ridge regression may perform poorly when the predictor variables are highly correlated, as it will reduce the magnitude of all of the correlated variables, rather than selecting only one of them.
Overall, Ridge regression is a useful tool for reducing the complexity of a regression model and automatically reducing the magnitude of the coefficients.
Difference between Lasso and Ridge Regression
Lasso and Ridge regression are two types of regularized regression, which use regularization terms in the cost function to penalize the complexity of the model. The main difference between the two is the form of the regularization term. Lasso regression uses the L1 norm, which adds a penalty based on the absolute value of the coefficients, while Ridge regression uses the L2 norm, which adds a penalty based on the squared value of the coefficients.
This difference in the regularization term leads to several key differences between Lasso and Ridge regression. For example, Lasso regression is more effective at automatically selecting the most important predictor variables and ignoring the less important ones, while Ridge regression is more effective at reducing the magnitude of the coefficients of all of the predictor variables. Additionally, Lasso regression may perform poorly when the predictor variables are highly correlated, while Ridge regression may perform poorly when the number of predictor variables is small.
Overall, Lasso and Ridge regression are similar in that they both use regularization to penalize the complexity of the model, but they differ in the form of the regularization term and the resulting behavior of the model. Depending on the specific characteristics of the data and the relationship between the predictor variables, one of these methods may be more appropriate than the other.
Bayesian Linear Regression
Bayesian linear regression is a type of linear regression that uses Bayesian statistics to make inferences about the model parameters. In Bayesian linear regression, the model parameters are treated as random variables, and a probability distribution is used to represent our uncertainty about their values. This allows the model to incorporate prior knowledge and make more accurate predictions based on the data.
Bayesian linear regression is useful in situations where you have prior knowledge about the model parameters, or where you want to incorporate uncertainty in the model predictions. For example, if you have previously collected data on the relationship between the dependent and independent variables, you can use this data to inform the prior distribution of the model parameters in a Bayesian linear regression model. This can improve the model's performance and make more accurate predictions.
On the other hand, Bayesian linear regression may not be the best choice in situations where you do not have prior knowledge about the model parameters, or where you do not need to incorporate uncertainty in the model predictions. In these cases, a standard linear regression model may be more appropriate, as it is simpler and faster to train. Additionally, Bayesian linear regression can be computationally expensive, so it may not be practical for very large datasets.
Why do we normalize data in Machine Learning?
Normalizing data in machine learning is the process of scaling the data so that it has a mean of zero and a standard deviation of one. This is typically done to improve the performance of the machine learning model, by ensuring that the data is in a standardized range and allowing the model to learn more effectively.
There are several reasons why normalizing data can be beneficial in machine learning. For example, normalizing the data can improve the convergence speed of the model, by reducing the range of the data and making it easier for the model to learn. Additionally, normalizing the data can prevent certain features from dominating the training process, by ensuring that all of the features are on a similar scale and contributing equally to the model's predictions.
Furthermore, normalizing the data can help prevent overfitting, by ensuring that the model is not sensitive to the specific scales of the features. This can help the model learn more generalizable patterns in the data, and improve its performance on new, unseen data.
In which cases, we don't need to normalize the data?
t is generally a good idea to normalize your data when working with machine learning algorithms. Normalization can help improve the performance of some algorithms, and can also make it easier to compare different data sets. However, there may be some cases where normalization is not necessary. For example, if you are working with algorithms that are not sensitive to the scale of the data, or if the data is already in a normalized format, then normalization may not be necessary. Additionally, if you are working with data that has a natural ordinal relationship, such as grades or rankings, then normalization may not be necessary. It is always a good idea to evaluate your specific use case and data to determine if normalization is necessary.
There are several algorithms that are not sensitive to the scale of the data, and therefore may not require data normalization. Some examples of these algorithms include decision trees, random forests, and support vector machines with linear kernels. These algorithms are not sensitive to the scale of the data because they do not rely on distance measures to make predictions. In these cases, normalization may not be necessary, and could even be detrimental if it distorts the natural relationship between the features in the data. Again, it is always a good idea to evaluate your specific use case and data to determine if normalization is necessary.
What's the difference between data normalization and standardization?
Data normalization and data standardization are two techniques that are often used to pre-process data before it is used in machine learning algorithms. Both techniques are useful for transforming the data in a way that can improve the performance of the algorithms, but they are used for different purposes.
Data normalization is a technique that is used to scale the data so that it is within a specific range, such as 0 to 1. This is done by subtracting the minimum value from each data point and then dividing by the range of the data (the maximum value minus the minimum value). This transformation can help improve the performance of some machine learning algorithms, particularly those that use distance measures, because it ensures that all of the data is on the same scale.
Data standardization, on the other hand, is a technique that is used to transform the data so that it has a mean of 0 and a standard deviation of 1. This is done by subtracting the mean from each data point and then dividing by the standard deviation. This transformation can also help improve the performance of some machine learning algorithms, particularly those that are sensitive to the scale of the data.
When to use data normalization and when to use data standardization?
As a general rule, data normalization is a good technique to use when you want to scale the data to a specific range, such as 0 to 1. This can be useful for algorithms that are sensitive to the scale of the data, such as algorithms that use distance measures. Data standardization, on the other hand, is a good technique to use when you want to transform the data so that it has a mean of 0 and a standard deviation of 1. This can be useful for algorithms that are sensitive to the distribution of the data, such as algorithms that assume that the data is normally distributed.
Normalization -> Data distribution is not Gaussian (bell curve). Typically applies in KNN, ANN
Standardization -> Data distribution is Gaussian (bell curve). Typically applies in Linear regression, logistic regression.
Note: Algorithms like Random Forest (any tree based algorithm) does not require feature scaling.
What are some dimensionality reduction algorithms?
Dimensionality reduction is a technique used to reduce the number of features in a data set, while retaining as much of the relevant information as possible. There are many different algorithms that can be used for dimensionality reduction, and the appropriate algorithm to use will depend on the specific characteristics of the data and the goals of the analysis. Some of the most common dimensionality reduction algorithms include:
- Principal Component Analysis (PCA): PCA is a linear dimensionality reduction algorithm that projects the data onto a lower-dimensional space by maximizing the variance of the data along the principal components. This can be useful for reducing the number of features in the data while retaining as much of the original information as possible.
- Singular Value Decomposition (SVD): SVD is a matrix factorization technique that can be used for dimensionality reduction. It decomposes the data matrix into three matrices, which can then be used to project the data onto a lower-dimensional space.
- Linear Discriminant Analysis (LDA): LDA is a supervised dimensionality reduction algorithm that projects the data onto a lower-dimensional space by maximizing the separation between different classes in the data. This can be useful for improving the performance of classification algorithms.
- t-distributed Stochastic Neighbor Embedding (t-SNE): t-SNE is a non-linear dimensionality reduction algorithm that projects the data onto a lower-dimensional space by preserving the local structure of the data. This can be useful for visualizing high-dimensional data and for uncovering patterns in the data.
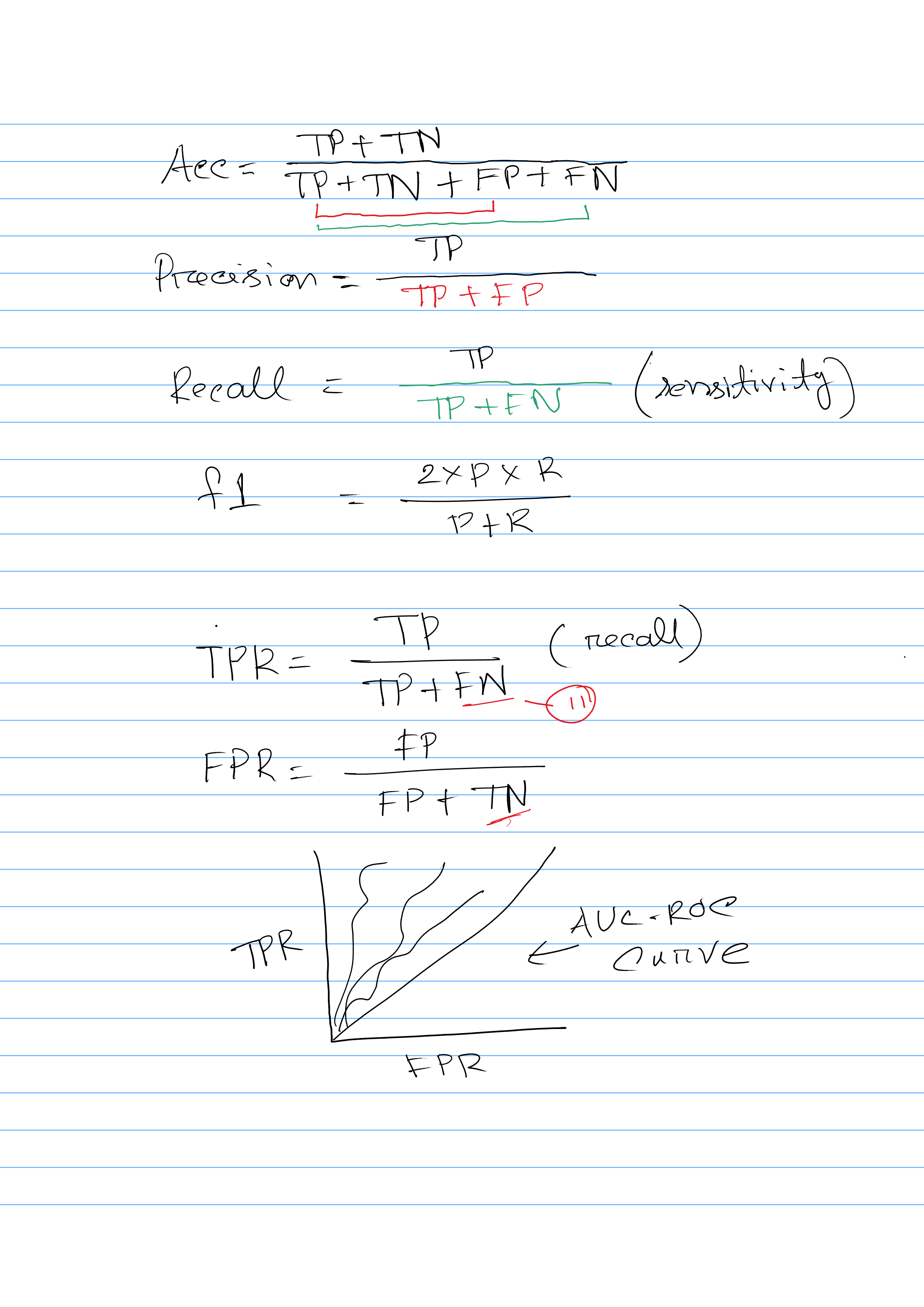
Explain Confusion Matrix
A confusion matrix is a table that is often used to describe the performance of a classification algorithm. It provides a detailed breakdown of the correct and incorrect predictions made by the algorithm, allowing you to see how well the algorithm is performing and where it might be making mistakes.
A confusion matrix has four main elements: true positives, true negatives, false positives, and false negatives. True positives are the number of correct predictions that the algorithm made for the positive class. True negatives are the number of correct predictions that the algorithm made for the negative class. False positives are the number of incorrect predictions that the algorithm made for the positive class (i.e. it predicted that the sample was positive, but it was actually negative). False negatives are the number of incorrect predictions that the algorithm made for the negative class (i.e. it predicted that the sample was negative, but it was actually positive).
Different evaluation metric calculation
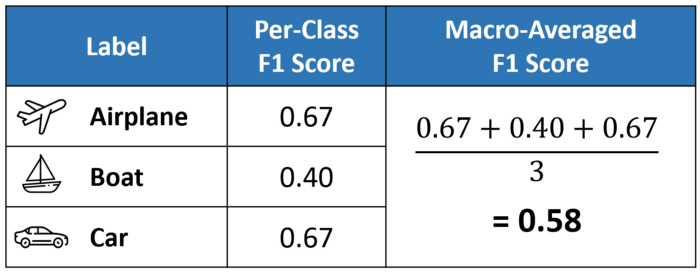
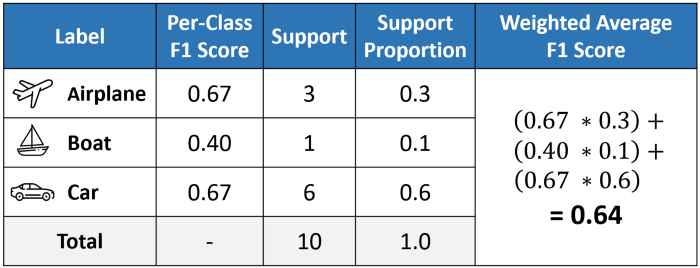
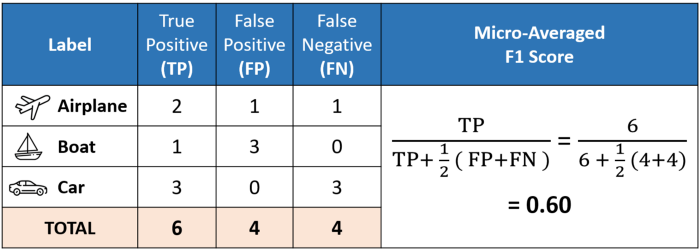
Difference among micro, macro, weighted f1-score
Excellent explanation: medium
When to use Precision vs Recall vs f1-score
F1-score
When deciding which metric to use, you need to consider the specific goals of your analysis and the potential consequences of false positive and false negative predictions. If you want to minimize false positives, then you should use precision as a metric. If you want to minimize false negatives, then you should use recall as a metric. If avoiding both false positives and false negatives are equally important, then you should use the f1 score as a metric, which is the harmonic mean of precision and recall.
Precision
In some cases, it may be more important to avoid false positives than false negatives. For example, if you are building an AI system to identify criminals in a housing society, then you want to avoid arresting innocent people (false positives), because this could lead to injustice. In this case, you should optimize your model using precision as a metric.
Recall
In other cases, it may be more important to avoid false negatives than false positives. For example, if you are building a security system to screen people for weapons at an airport, then you want to avoid letting dangerous people onto the plane (false negatives), because this could compromise the safety of passengers. In this case, you should optimize your model using recall as a metric.
When to use F1 as a evaluation metric?
The F1 score is a metric that is commonly used to evaluate the performance of a classification model. It is the harmonic mean of the model's precision and recall, which are both calculated by taking the number of true positive predictions by the model and dividing it by the total number of positive predictions made by the model. This means that the F1 score takes into account both the number of false positives and false negatives that the model produces.
One advantage of using the F1 score is that it is a balanced metric, which means that it considers both precision and recall equally. This is useful when you want to avoid a model that has a high precision but low recall, or vice versa. For example, in a medical diagnosis scenario, a model with high precision but low recall may not be useful because it may miss many cases of the disease that it is trying to detect.
When to use AUC-ROC as an evaluation metric?
The AUC-ROC (area under the receiver operating characteristic curve) is a metric that is commonly used to evaluate the performance of a binary classification model. It measures the ability of the model to distinguish between the positive and negative classes.
One advantage of using the AUC-ROC metric is that it is independent of the classification threshold, which means that it is not affected by changes in the threshold used to make predictions. This is useful when you want to compare the performance of different models on the same dataset, or when you want to compare the performance of the same model on different datasets.
Another advantage of the AUC-ROC metric is that it is not sensitive to class imbalance, which means that it can be used when there are unequal numbers of positive and negative instances in the dataset. This is useful when you are working with datasets that have imbalanced classes.
What are the differences between Random Forest and Gradient Boosting?
Random Forest and Gradient Boosting are two popular ensemble learning methods that are used for supervised learning tasks, such as classification and regression. Both methods use multiple decision trees to make predictions, but they differ in the way that the trees are trained and combined.
One key difference between Random Forest and Gradient Boosting is the way that the trees are trained. In Random Forest, the trees are trained independently using a random subsample of the training data. In contrast, in Gradient Boosting, the trees are trained sequentially, with each tree trying to correct the mistakes of the previous tree. This means that the trees in a Gradient Boosting model are more correlated than the trees in a Random Forest model.
Another key difference is the way that the trees are combined to make predictions. In Random Forest, the predictions of all the trees are combined using a majority vote. This means that the final prediction is the class that is predicted by the majority of the trees. In contrast, in Gradient Boosting, the predictions of the trees are combined using a weighted average, where the weights are determined by the performance of each tree.
In general, Random Forest is a good choice for tasks where the goal is to build a robust and accurate model with a low degree of overfitting. It is also a good choice when you have a large number of features in your dataset. In contrast, Gradient Boosting is a good choice for tasks where the goal is to build a highly accurate model, even at the cost of some overfitting.
What's the difference between loss function and cost function?
In machine learning, a loss function and a cost function are similar but distinct concepts. A loss function is a measure of how well a model is able to predict the true values of the target variable given the input data. It quantifies the error between the predicted values and the true values, and is used to guide the training of the model.
In contrast, a cost function is a measure of how well the model is able to make predictions on new data, given the training data. It is a function of the model's parameters, and is used to evaluate the performance of the model.
In other words, a loss function is used to measure the performance of a model on a given training dataset, while a cost function is used to evaluate the performance of the model on unseen data. The loss function is used to update the model's parameters during training, while the cost function is used to compare the performance of different models or the same model with different parameter settings.
In summary,
- The loss function is to capture the difference between the actual and predicted values for a single record
- Whereas cost functions aggregate the difference for the entire training dataset. To do this it aggregates the loss values that are calculated per observation.
A loss function is a part of a cost function.
How do you evaluate the performance of a machine learning model?
There are several ways to evaluate the performance of a machine learning model, including:
- Measuring the model's accuracy: This involves calculating the proportion of correct predictions made by the model on a test dataset. This is a good measure of performance for classification problems, but can be less reliable for regression problems.
- Calculating the model's error: This involves calculating the difference between the predicted values and the true values on the test dataset. This can be done using metrics such as the mean squared error (MSE) for regression problems, or the cross-entropy loss for classification problems.
- Using metrics specific to the type of problem: For example, in a classification problem, metrics such as precision, recall, and F1 score can be used to evaluate the model's performance. In a clustering problem, metrics such as the silhouette score or the Calinski-Harabasz index can be used to evaluate the model's performance.
- Visualizing the model's predictions: This involves creating plots such as scatter plots or histograms to compare the predicted values and the true values. This can help identify patterns and trends in the data and assess the model's performance.
Overall, the choice of evaluation metrics will depend on the specific problem and the goals of the model. It is important to select evaluation metrics that are appropriate for the task and that align with the model's intended use.
Can you describe the concept of regularization and how it can be used to prevent overfitting?
Regularization is a technique used in machine learning to prevent overfitting by adding a penalty term to the loss function of a model. This penalty term, called the regularization term, is typically added to the loss function in the form of a weighted sum of the model's parameters, where the weights are chosen such that large parameter values are penalized more heavily than small ones. This serves to reduce the complexity of the model, which in turn helps to prevent overfitting by limiting the ability of the model to fit the noise in the training data. There are several different types of regularization that can be used, including L1 regularization, L2 regularization, and elastic net regularization.
What is the difference between L1 regularization and L2 regularization
L1 regularization is a technique used in machine learning to prevent overfitting by adding a regularization term to the loss function of a model. The regularization term is the sum of the absolute values of the model's parameters, multiplied by a constant called the regularization parameter. This can be written mathematically as follows:
1L1 regularization term = regularization_parameter * sum(|parameters|)
where regularization_parameter is a hyperparameter that determines the strength of the regularization, and parameters is a vector of the model's parameters.
L2 regularization is another technique used to prevent overfitting by adding a regularization term to the loss function. In L2 regularization, the regularization term is the sum of the squares of the model's parameters, multiplied by a constant called the regularization parameter. This can be written mathematically as follows:
1L2 regularization term = regularization_parameter * sum(parameters^2)
where regularization_parameter is a hyperparameter that determines the strength of the regularization, and parameters is a vector of the model's parameters.
Both L1 and L2 regularization are used to reduce the complexity of a model and prevent overfitting, but they do so in different ways.
-
L1 regularization encourages the model to use only a subset of its features.
-
While L2 regularization discourages the model from using very large parameter values.
How do you handle missing or incorrect data in your data science project?
There are several approaches that can be used to handle missing data in a data science project, depending on the specific needs of the project and the goals of the analysis. Some common approaches include:
-
Removing rows or columns that contain missing data: This approach can be useful if the missing data is not representative of the overall dataset, or if the amount of missing data is relatively small.
-
Imputing the missing data using a statistical method: This approach can be useful if the missing data is not random, and if there is a clear pattern or relationship between the missing data and other values in the dataset.
-
Using data from a different source to fill in the missing data: This approach can be useful if there is another dataset that contains information that is relevant to the missing data, and if it is possible to combine the two datasets in a meaningful way.
-
Ignoring the missing data and proceeding with the analysis using only the available data: This approach can be useful if the amount of missing data is relatively small, and if it is not likely to significantly impact the results of the analysis.
-
If there are outliers in the data, we can replace the missing data with median of the feature.
-
Better way would be to use KNN to find the similar observations/samples, and then replace missing values with their (similar samples) average.
KNN works better for numerical data.
How do you handle large datasets?
- Sampling: This involves selecting a representative subset of the data to work with, rather than using the entire dataset. This can be useful if the dataset is too large to work with efficiently, or if the patterns and trends in the data can be accurately represented by a smaller sample.
- Parallel processing: This involves using multiple computers or processors to perform the analysis simultaneously, rather than using a single processor. This can be useful if the dataset is too large to fit into the memory of a single computer, or if the analysis requires a lot of computational power.
- Data reduction: This involves applying techniques such as feature selection or dimensionality reduction to reduce the number of variables or features in the dataset. This can be useful if the dataset contains a large number of redundant or irrelevant variables, or if the analysis can be performed more efficiently with a smaller number of variables.
- Data partitioning: This involves dividing the dataset into smaller subsets and performing the analysis on each subset separately. This can be useful if the dataset is too large to work with efficiently, or if the analysis can be performed more efficiently in smaller chunks.
How do you stay up-to-date with the latest developments in data science and machine learning?
There are several ways to stay up-to-date with the latest developments in data science and machine learning. Some common approaches include:
- Following notable people on Twitter who are working with AI/ML technologies. They usually share a lot of news about new trends in the industry and academia.
- Reading books and articles on data science and machine learning: This can help you stay current with the latest theories, techniques, and applications in the field.
- Attending conferences and workshops: This can provide you with opportunities to learn from experts in the field, and to network with other professionals working in data science and machine learning.
- Joining online communities and forums: This can provide you with access to a wealth of knowledge and resources, and can also provide opportunities to connect with other data scientists and machine learning professionals.
- Participating in online courses and training programs: This can provide you with structured learning experiences, and can also help you stay up-to-date with the latest tools and technologies in the field.
- Staying current with industry news and trends: This can help you stay informed about the latest developments and innovations in the field, and can also provide valuable insights into how data science and machine learning are being used in the real world.
How dimensionality reduction work in Machine Learning
Dimensionality reduction is a technique that is used in machine learning to reduce the number of features or dimensions in a dataset. This is useful because it can make the data easier to work with and analyze, and can also improve the performance of machine learning algorithms.
There are several ways that dimensionality reduction can be implemented in machine learning, including:
- Feature selection: This involves selecting a subset of the most important features from the dataset, and removing the others. This can be useful if the dataset contains a large number of redundant or irrelevant features, or if the analysis can be performed more efficiently with a smaller number of features.
- Principal component analysis (PCA): This is a statistical technique that uses linear algebra to transform the data into a new space with fewer dimensions, while preserving as much of the original variance in the data as possible. This can be useful if the data is highly correlated, or if there is a strong linear relationship between the features.
- Autoencoders: These are artificial neural networks that are trained to learn a compact representation of the data, by encoding the data into a lower-dimensional space and then decoding it back into the original space. This can be useful if the data is non-linear, or if there is a complex relationship between the features.
How PCA works?
Principal component analysis (PCA) is a statistical technique that is often used for dimensionality reduction in machine learning. It is a method that uses linear algebra to transform the data into a new space with fewer dimensions, while preserving as much of the original variance in the data as possible.
Here is a step-by-step explanation of how PCA works for dimensionality reduction:
- Standardize the data: The first step is to standardize the data by subtracting the mean from each feature and dividing by the standard deviation. This is necessary because PCA is sensitive to the scale of the data, and standardizing the data ensures that all the features are on the same scale.
- Compute the covariance matrix: The next step is to compute the covariance matrix of the standardized data. This is a square matrix that contains the pairwise covariances between all the features in the data.
- Compute the eigenvectors and eigenvalues: The next step is to compute the eigenvectors and eigenvalues of the covariance matrix. The eigenvectors are the directions in the data space along which the data varies the most, and the eigenvalues are the corresponding magnitudes of the variations.
- Select the eigenvectors with the highest eigenvalues: The next step is to select the eigenvectors with the highest eigenvalues, as these are the directions in the data space that capture the most variance.
- Transform the data into the new space: The final step is to transform the data into the new space defined by the selected eigenvectors. This is done by computing the dot product of the standardized data and the eigenvectors, which projects the data onto the new space.
By using PCA for dimensionality reduction, data scientists and machine learning professionals can reduce the complexity of the data, and improve the performance of machine learning algorithms. Additionally, PCA can also be used to visualize high-dimensional data in a lower-dimensional space, which can help to gain insights into the underlying structure of the data.
What are the different types of data distribution in statistics?
In statistics, data can be distributed in many different ways, depending on the characteristics of the data and the underlying population. Some common distributions of data include:
- Normal distribution: This is a symmetrical distribution that is often described as a bell-shaped curve. It is commonly used to model data that is continuous and normally distributed, such as height, weight, or IQ.
- Binomial distribution: This is a distribution that is used to model data that can take on only two possible values, such as success or failure, or heads or tails. It is commonly used to model the probability of a certain number of successes in a given number of trials.
- Poisson distribution: This is a distribution that is used to model data that represents the number of events that occur in a given time or space. It is commonly used to model data that is discrete and counts the number of occurrences of an event, such as the number of accidents on a highway or the number of defects in a manufacturing process.
- Exponential distribution: This is a distribution that is used to model data that is continuous and has a constant rate of change. It is commonly used to model data that represents the time between events, such as the time between arrivals at a bus stop or the time between failures of a machine.
- Uniform distribution: This is a distribution that is used to model data that is continuous and has an equal probability of occurring within a given range. It is commonly used to model data that is randomly generated, such as the results of a dice roll or a random number generator.
What are some clustering algorithm in Machine Learning?
Clustering is a technique that is used to group data points into clusters based on their similarity. This can be useful for a variety of applications, such as image segmentation, customer segmentation, and anomaly detection. Some common clustering algorithms include:
- K-means: This is a popular and widely-used clustering algorithm that is based on the idea of partitioning the data into a specified number of clusters, and then iteratively refining the cluster assignments until the clusters are as compact and well-separated as possible.
- Hierarchical clustering: This is a clustering algorithm that is based on the idea of building a hierarchy of clusters, where each cluster is split into smaller clusters until each data point belongs to a single-point cluster.
- DBSCAN: This is a clustering algorithm that is based on the idea of finding dense clusters of data points in the data space, and then expanding the clusters to include points that are nearby.
- Expectation-maximization (EM): This is a clustering algorithm that is based on the idea of fitting a mixture model to the data, where each component of the mixture represents a different cluster.
What are the different feature selection procedures in Machine Learning?
- Correlation-based Feature Selection: This technique calculates the correlation between each feature and the target variable and only keeps the features with a high correlation. This can be useful for removing redundant features that add little predictive power to the model.
- Wrapper-based Feature Selection: This technique uses a predictive model to evaluate each feature's importance, then selects the features that improve the model's performance. This is a more computationally intensive method, but it can be effective for selecting the most relevant features.
- Embedded-based Feature Selection: This technique trains a predictive model and then uses the model's weights to determine each feature's importance. Features with high absolute weight are important and retained in the model. This is a good method for selecting useful features for making predictions.
- Recursive Feature Elimination (RFE): This technique recursively removes features, builds a model using the remaining features, and then evaluates the model's performance. The process is repeated until only the most relevant features are left.
- Principal Component Analysis (PCA): This technique projects the data onto a lower-dimensional space and selects the most important principal components for building the model. This can be useful for reducing the dimensionality of the data and removing irrelevant features.
In general, the best approach for feature selection will depend on the specific dataset and the type of model being used. It is important to experiment with different methods to find the one that works best for your particular situation.
How to select features for a xgboost model?
To select features for a xgboost model, you can use the SelectFromModel method, which is part of the scikit-learn library. This method allows you to specify a threshold for feature importance, and then automatically selects the features that meet or exceed that threshold.
1import xgboost as xgb
2from sklearn.feature_selection import SelectFromModel
3
4# Train your xgboost model
5model = xgb.XGBClassifier()
6model.fit(X_train, y_train)
7
8# Use SelectFromModel to select features with a minimum importance value of 0.2
9selection = SelectFromModel(model, threshold=0.2)
10selected_features = selection.transform(X_train)
11
12# Train a new model using only the selected features
13new_model = xgb.XGBClassifier()
14new_model.fit(selected_features, y_train)
The SelectFromModel method is used to select all of the features that have an importance value of at least 0.2, as determined by the trained xgboost model. These selected features are then used to train a new xgboost model.
You can adjust the threshold value to select more or fewer features, depending on your needs. It's generally a good idea to use a relatively low threshold value, to ensure that you are selecting as many relevant features as possible. However, if your dataset has a large number of features and you want to reduce the number of features for computational efficiency, you can use a higher threshold value to select only the most important features.
How Neural Networks work?
Neural networks are a type of machine learning algorithm that are inspired by the structure and function of the human brain. They are composed of many interconnected processing units, called neurons, that are arranged into layers. The neurons in the input layer receive input data, and the neurons in the output layer produce the final output of the network. The neurons in the hidden layers process the data and pass it on to the next layer.
Step-by-step explanation of how a neural network works:
- Initialize the weights: The first step is to initialize the weights of the connections between the neurons in the network. The weights are typically initialized to small random values, in order to break any symmetry in the network and allow the network to learn from the data.
- Feed the input data through the network: The next step is to feed the input data through the network, by passing the data from the input layer to the first hidden layer. At each layer, the neurons compute a weighted sum of the inputs, and then apply an activation function to the sum in order to produce an output.
- Propagate the output through the network: The next step is to propagate the output of each layer through the network, by passing the output from one layer to the next. This continues until the output of the final layer is produced, which represents the final output of the network.
- Calculate the error: The next step is to calculate the error between the actual output of the network and the desired output. This error is used to measure the performance of the network and to guide the learning process.
- Adjust the weights: The final step is to adjust the weights of the connections between the neurons in the network in order to reduce the error. This is typically done using a gradient descent algorithm, which computes the gradient of the error with respect to the weights and updates the weights in the direction that reduces the error.
By repeating these steps, the neural network can learn from the data and improve its performance over time. As the network learns, the weights of the connections between the neurons are adjusted in order to capture the underlying patterns and relationships in the data. This allows the network to make accurate predictions and decisions based on the input data.
What are the building blocks of a Convolutional neural networks (CNNs)
Convolutional neural networks (CNNs) are a type of neural network that is specifically designed to work with data that has a grid-like structure, such as an image. CNNs are composed of multiple layers of interconnected neurons, where the neurons in each layer are arranged in a three-dimensional grid. The building blocks of a CNN include:
- Input layer: The input layer receives the input data and passes it on to the first hidden layer. In the case of an image, the input layer consists of multiple neurons, each representing a pixel in the image.
- Hidden layers: The hidden layers are composed of multiple neurons arranged in a three-dimensional grid. Each neuron in a hidden layer receives inputs from a small region of the previous layer, and produces an output that is passed on to the next layer.
- Convolutional layers: In a CNN, the hidden layers typically include convolutional layers, where the neurons perform a convolution operation on the input data. This involves applying a small kernel or filter to the input data, which extracts features from the data and passes them on to the next layer.
- Pooling layers: The hidden layers of a CNN may also include pooling layers, where the neurons perform a down-sampling operation on the input data. This involves summarizing the input data in some way, such as taking the maximum or average value, in order to reduce the dimensionality of the data and make the network more robust to changes in the input data.
- Fully-connected layers: The final hidden layers of a CNN are typically fully-connected, where each neuron receives inputs from all the neurons in the previous layer. This allows the network to combine the extracted features from the convolutional and pooling layers, and make a prediction or decision based on the input data.
- Output layer: The output layer produces the final output of the network. In the case of an image classification task, the output layer may consist of multiple neurons, each representing a different class. The output of the network is the predicted class of the input image.
How to calculate the number of parameters and output shape size for CNN?
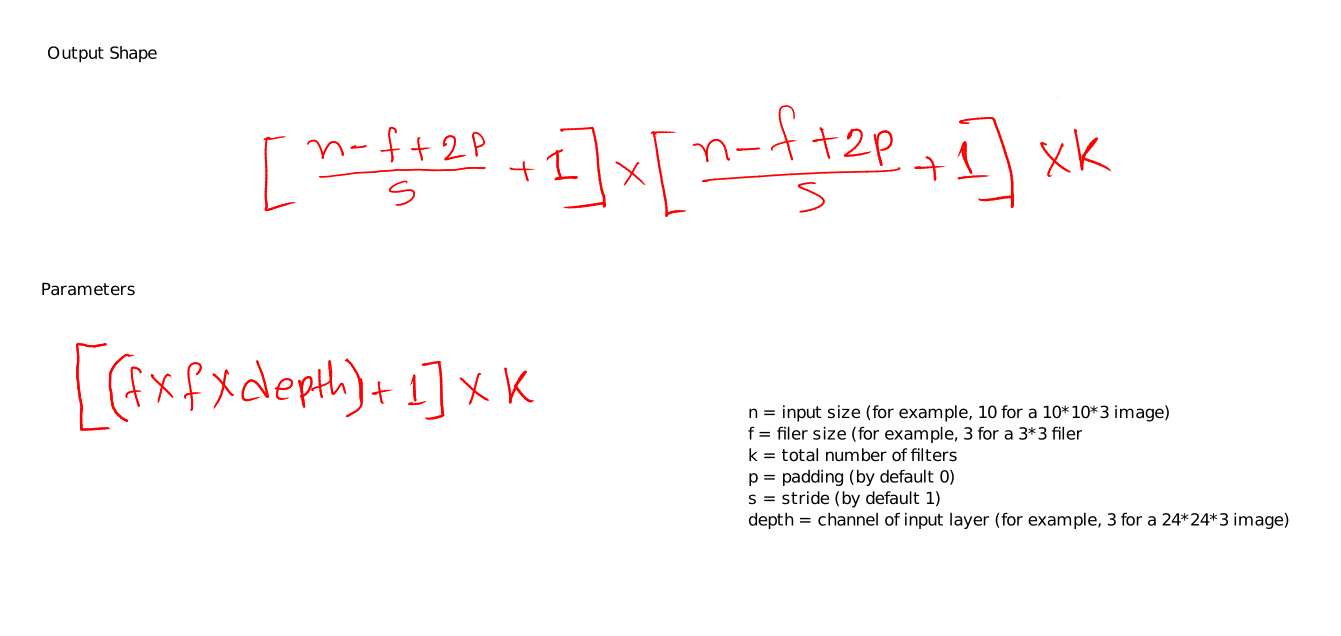
What are some of the state-of-the-art Computer Vision models
- ResNet: This is a deep convolutional neural network that is trained on large datasets and is capable of achieving high accuracy on many tasks.
- DenseNet: This is another deep convolutional neural network that is known for its ability to efficiently learn complex representations.
- Inception: This is a model that uses a combination of convolutional and pooling layers to learn features from images.
- Mask R-CNN: This is a model that is specifically designed for object detection and instance segmentation, which involves identifying and segmenting individual objects in an image.
- GANs: Generative adversarial networks are a class of models that can be used to generate new images based on a given input.
- YOLO (You Only Look Once): This is a fast object detection model that can be used to identify objects in real-time.
- R-CNN (Regional Convolutional Neural Network): This is a model that uses region proposal algorithms to identify objects in an image and then uses a CNN to classify the objects.
- SSD (Single Shot Detector): This is a model that combines a CNN with a regression layer to identify objects in an image.
- U-Net: This is a model that is specifically designed for image segmentation, which involves dividing an image into multiple segments or regions.
- VGG (Visual Geometry Group): This is a model that uses a series of convolutional and pooling layers to learn features from images.
What is the difference between batch prediction and online prediction?
Batch prediction and online prediction are two different methods for making predictions using machine learning models.
Batch prediction involves using a trained machine learning model to make predictions on a large batch of data all at once. This is typically done by feeding the entire dataset into the model, and then using the model to make predictions on each data point in the batch. Batch prediction is useful when the dataset is large and the predictions can be made in parallel, as it can be more efficient than making predictions one at a time.
Online prediction involves using a trained machine learning model to make predictions on individual data points as they are received. This is useful when the data is streaming or the predictions need to be made in real-time, as it allows the model to make predictions on the fly.
Give a real-life example of when to use batch inference and when to use online inference
Batch inference is typically used when you have a large amount of data that you need to process all at once, such as when you are running a machine learning model on a dataset to make predictions. Online inference, on the other hand, is used when you need to make predictions on individual data points in real-time, such as when you are using a speech-to-text model to transcribe audio in real-time.
For example, if you are building a system to classify images, you might use batch inference to process a dataset of images and train a machine learning model. Once the model is trained, you could then use online inference to classify new images as they come in, in real-time.
Another example might be a website that uses a machine learning model to recommend products to customers. In this case, you could use batch inference to process the entire catalog of products and train a recommendation model, and then use online inference to generate personalized recommendations for individual users as they browse the website.
How to reduce the prediction serving latency in Machine Learning?
There are a few different ways to reduce the prediction serving latency in machine learning, including the following:
- Optimize the model for inference: One way to reduce the prediction serving latency is to optimize the model for inference. This can involve techniques such as quantizing the model to reduce the number of bits used to represent the weights, or pruning the model to remove redundant or unnecessary connections.
- Use a faster hardware platform: Another way to reduce the prediction serving latency is to use a faster hardware platform for serving the model. For example, you could use a high-performance GPU or a custom ASIC designed for machine learning inference to speed up the processing of predictions.
- Use a faster inference algorithm: Some machine learning models can be served using different inference algorithms, which can have different performance characteristics. Choosing a faster inference algorithm can help reduce the prediction serving latency.
- Use a cache: If your model is serving a large number of requests, it can be helpful to use a cache to store the results of previous predictions. This can allow you to quickly serve the same request multiple times without having to re-run the entire model.
- Use a distributed serving architecture: Finally, using a distributed serving architecture can also help reduce the prediction serving latency. This involves running multiple instances of the model on different machines, and using a load balancer to distribute incoming requests across the different instances. This can help reduce the time it takes to serve each individual request.
Explain how pre-trained BERT embeddings are generated.
Pretrained BERT embeddings are generated by training a BERT model on a large corpus of text data. The BERT model is a type of Transformer-based neural network that is designed to process and understand natural language. During training, the model learns to generate a numerical representation, or embedding, for each word in the training corpus. These word embeddings capture the semantic meaning of the words and can be used as input to other natural language processing models.
How do the pre-trained weights understand completely new word representation?
Pretrained BERT models are not specifically designed to understand completely new words that they have not seen during training. Instead, they rely on a process called subword tokenization, which breaks words down into smaller pieces called subwords. For example, the word "unexpected" might be broken down into the subwords "un", "expect", and "ed". The BERT model can then generate an embedding for each subword, which can be combined to represent the overall meaning of the original word. This allows the model to generalize to words that it has not seen in the training data, by using the subwords that it has learned to represent similar words.
What's the workflow of a text summarization in NLP using pre-trained weights
The workflow of a text summarization model using pretrained weights would generally involve the following steps:
- Preprocessing the input text data to clean and prepare it for input to the model. This may involve tokenizing the text, removing punctuation and stop words, and extracting important keywords and phrases.
- Loading the pretrained weights into the model, which would have been trained on a large corpus of text data.
- Feeding the preprocessed input text into the model, which would generate a numerical representation, or embedding, for each word in the text.
- Using the word embeddings as input to the summarization model, which would generate a summary of the input text. This summary may be a shorter version of the original text, or it may highlight the most important points in the text.
- Postprocessing the output summary to clean and format it, and outputting it in the desired format.
This is a general outline of the process, and specific implementations may vary depending on the details of the model and the data.
What are the different approaches to generating word embeddings in NLP
- Word2Vec: This is a popular method for learning word embeddings by predicting the surrounding words in a sentence or phrase.
- GloVe: This method learns word embeddings by training a model to predict the co-occurrence of words in a corpus of text data.
- FastText: This method learns word embeddings by training a model to predict the words in a sentence, based on the characters in the words.
- BERT: This method uses a transformer-based neural network to learn word embeddings by training on a large corpus of text data.
How to generate embeddings for a Computer Vision task?
To generate embeddings for a computer vision task, you would typically use a convolutional neural network (CNN) to extract features from the input images. The CNN would be trained on a large dataset of images, and during training, it would learn to generate a numerical representation, or embedding, for each image. This embedding would capture the key features of the image, and could be used as input to other machine learning models for tasks such as image classification or object detection.
To generate the embeddings, you would first preprocess the input images by resizing them to a fixed size and converting them to a format that is suitable for input to the CNN. You would then feed the preprocessed images into the CNN, which would generate the embeddings. These embeddings could then be used as input to other machine learning models for downstream tasks.
What's the difference between the BERT model and the SBERT model?
BERT, or Bidirectional Encoder Representations from Transformers, is a type of transformer-based neural network that is designed to process and understand natural language. SBERT, or Sentence-BERT, is a variation of BERT that is specifically designed to encode sentences rather than individual words. This allows SBERT to capture the meaning of entire sentences, rather than just the individual words, which can be useful for certain natural language processing tasks such as sentiment analysis or text classification.
One key difference between the BERT and SBERT models is the input data that they are designed to process. BERT is typically trained on a large corpus of text data and is designed to generate word embeddings, which capture the semantic meaning of individual words. In contrast, SBERT is trained to generate sentence embeddings, which capture the meaning of entire sentences. This allows SBERT to better capture the context and meaning of sentences, which can be useful for certain natural language processing tasks.
Another key difference between the two models is their performance and accuracy. BERT is a highly accurate model, but it is designed to process individual words, so it may not always capture the meaning of longer phrases or sentences. SBERT, on the other hand, is specifically designed to process entire sentences, so it may be more accurate for tasks that require understanding the meaning of longer phrases or sentences. However, SBERT is a relatively new model, so its performance has not been extensively tested and evaluated.
Author: Sadman Kabir Soumik